Understanding MTBF in Maintenance: Its Meaning and Role in Predictive Strategies
April 29, 2025
In demanding mining and heavy processing environments, equipment reliability isn’t just a goal – it’s a necessity. Unplanned equipment failures can pose significant safety risks, lead to operational disruptions, and result in substantial financial losses. This reality applies to mobile assets, such as haul trucks operating at the mine face, as well as fixed assets like crushers, mills, and slurry pumps within processing plants and smelters. One of the pivotal metrics for assessing and enhancing equipment reliability is Mean Time Between Failures (MTBF).
But what does MTBF truly signify beyond its textbook definition? How can organizations utilize this metric to enhance their maintenance strategies and overall operational efficiency?
Understanding MTBF
Mean Time Between Failures (MTBF) is a fundamental reliability engineering metric that quantifies the average operational time between the inherent failures of a system or component. The formula is straightforward:
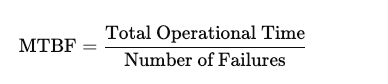
In practical terms, MTBF provides an estimate of the expected time an asset will operate before experiencing a failure. A higher MTBF indicates greater reliability, suggesting that the equipment is less likely to fail unexpectedly. This metric is invaluable for maintenance planning, inventory management, and scheduling, as it helps predict equipment behavior and plan interventions proactively.
MTBF and Planned/Unplanned Maintenance Ratio in the Mining Sector
In the mining and mineral processing industries, equipment downtime has direct and severe implications, resulting in lost production and increased financial risks. Essential machinery such as crushers, mills, centrifuges, fans, and pumps is integral to maintaining throughput. Even minor failures can have cascading effects throughout the operation.
Recent industry analyses underscore the financial impact of unplanned maintenance. According to a report by USC Consulting Group, unplanned maintenance activities can consume up to three times the resources, including labor, materials, and downtime costs, compared to planned maintenance. This disparity is not solely due to the immediate costs of repairs but also encompasses logistical delays, expedited procurement, misallocation of resources, and increased safety hazards associated with reactive maintenance approaches.
To mitigate these challenges, many mining operations are striving to shift their maintenance strategies from a reactive stance, often characterized by a 50/50 split between planned and unplanned maintenance, to a more proactive approach, aiming for ratios of 70/30 or better. Achieving such a shift is heavily dependent on strategies that effectively increase Mean Time Between Failures (MTBF).
Enhancing MTBF Through Predictive Maintenance
Improving MTBF requires more than adhering to traditional maintenance schedules or increasing the frequency of routine checks. It necessitates a deep understanding of early-stage failure modes – those subtle indicators that often go unnoticed by conventional monitoring methods.
This is where advanced platforms like DataMind AI™ become transformative.
By integrating data from multiple sensor types, including vibration, current, oil analysis, temperature, pressure, and visual inspections, DataMind AI employs sophisticated analytics and machine learning algorithms to provide real-time insights into asset health. This system is capable of detecting failure precursors weeks or even months in advance, offering maintenance teams detailed diagnostics that go beyond generic alerts.
Such predictive capabilities enable operations to:
- Precisely Plan Interventions: Maintenance activities can be scheduled based on the actual condition of the equipment, rather than estimated timelines, thereby reducing unnecessary downtime.
- Extend Operational Periods Between Failures: Early detection of potential issues enables corrective actions before they escalate, effectively increasing Mean Time Between Failures (MTBF).
- Optimize Component Usage: By understanding the actual condition of components, unnecessary replacements of still-functional parts can be avoided, leading to cost savings.
- Prioritize Actions Based on Severity: Focus maintenance efforts on the most critical issues to enhance overall operational efficiency.
Real-World Applications: Case Studies Demonstrating Positive Impact on Increasing MTBF
The theoretical benefits of increasing Mean Time Between Failures (MTBF) are compelling, but real-world applications provide tangible evidence of its impact. Below are examples from mining and processing sites where DataMind AI™ has directly contributed to extending Mean Time Between Failures (MTBF) and reducing unplanned downtime.
1. Ball Mill Gearbox – Preventing Gear Tooth Failure
At an iron ore processing site in South Australia, DataMind AI™ identified rising friction levels within a ball mill’s gearbox—an asset with a history of unexpected breakdowns. Initial diagnostics revealed abnormal vibrations around the 3Hz range. As the friction levels increased, the system escalated the alert status from “Alarm” to “Critical,” recommending a borescope inspection. This proactive approach allowed the maintenance team to schedule a planned gearbox replacement, averting a catastrophic failure.
- Downtime Prevented: 8 hours
- Financial Savings: Approximately $432,000
- Outcome: Gearbox damage was confirmed and addressed during the planned intervention.
2. Centrifuge Drum Imbalance – Early Detection Post-Maintenance
Following a routine shutdown at a coal processing facility, a centrifuge began exhibiting signs of imbalance. DataMind AI™ detected vibration anomalies corresponding to the drum’s operational frequency, indicating the presence of internal debris that had been overlooked during manual inspections. The maintenance team promptly removed the buildup, preventing further damage and restoring the equipment’s efficiency.
- Downtime Prevented: 6 hours
- Financial Savings: Approximately $271,560
- Outcome: Material flow efficiency was restored without unplanned interruptions.
View the centrifuge case study
3. Slurry Pump – Uncovering Hidden Bearing Friction Due to Lubrication Failure
In a scenario where manual testing failed to reveal issues, DataMind AI™ utilized high-frequency acceleration data and envelope demodulation techniques to detect elevated friction in the drive-end bearing of a slurry pump. The root cause was traced to lubrication degradation. Addressing this issue during a planned shutdown prevented component failure and secondary damage.
- Downtime Prevented: 6 hours
- Financial Savings: Approximately $195,000
- Outcome: The pump continued to operate reliably following the intervention.
4. Sinter Fan – Detecting Combined Lubrication and Mechanical Looseness Issues
At a chrome smelter, DataMind AI™ identified increasing friction and a rising noise floor in the drive-end bearing of a sinter fan. What initially appeared to be a lubrication issue was further diagnosed as mechanical looseness. Early detection allowed the maintenance team to address both issues before a failure occurred.
- Downtime Prevented: 7 hours
- Financial Savings: Approximately $455,000
- Outcome: Operational reliability was maintained without unexpected downtime.
MTBF as a Strategic Asset in Maintenance Management
Understanding and improving MTBF extends beyond theoretical discussions; it serves as a direct indicator of how effectively a site manages failures.
Want to see what this looks like for your plant? Let’s map your equipment list against historical Mean Time Between Failures (MTBF) and build a predictive roadmap for the future.
Or start by reviewing how other plants did it in the whole case studies archive.
Contact us




